https://www.udemy.com/aws-certified-solutions-architect-associate/learn/v4/t/lecture/5267844?start=0
https://d0.awsstatic.com/whitepapers/architecture/AWS_Well-Architected_Framework.pdf
Main Menu
Introduction – What is the Well Architected Framework?
Pillar 1 – Security
Pillar 2 – Reliability
Pillar 3 – Performance Efficiency
Pillar 4 – Cost Optimization
Pillar 5 – Operational Excellence
What is “The Well Architected Framework”
This has been developed by the Solutions Architecture team based on their experience with helping AWS customers. The well architected framework is a set of questions that you can use to evaluate how well your architecture is aligned to AWS best practices.
The Five Pillars of The Well Architected Framework
- Security
- Reliability
- Performance Efficiency
- Cost Optimization
- Operational Excellence
Structure of each pillar
- Design Principles
- Definition
- Best Practices
- Key AWS Services
- Resources
General Design Principles
- Stop guessing your capacity needs
- Think Auto-scaling from the word Go.
- Test systems at production scale
- Spin it up, test it, decommission it.
- Automate to make architectural experimentation easier
- Create and replicate with no additional effort
- Allow for evolutionary architectures
- Keep it dynamic and don’t lock yourself into bad architecture.
- Data-Driven architectures
- Use systems like CloudWatch to make fact based decisions regarding your architecture.
- Improve through game days
- Spin up a test environment to fully mimic your production, then test the heck out of it to see if it is ready to hold up under real life conditions.
Pillar 1 – Security
Design Principles
- Apply security at all layers (not just public facing firewalls!)
- Subnets -Network ACLs
- Load Balancers
- Individual EC2 instances
- Windows servers should have some sort of Anti-virus software.
- Enable Traceability
- CloudTrail
- Automate responses to security events
- Brute force attempts to Port 22
- WP admin or xmppa attacks
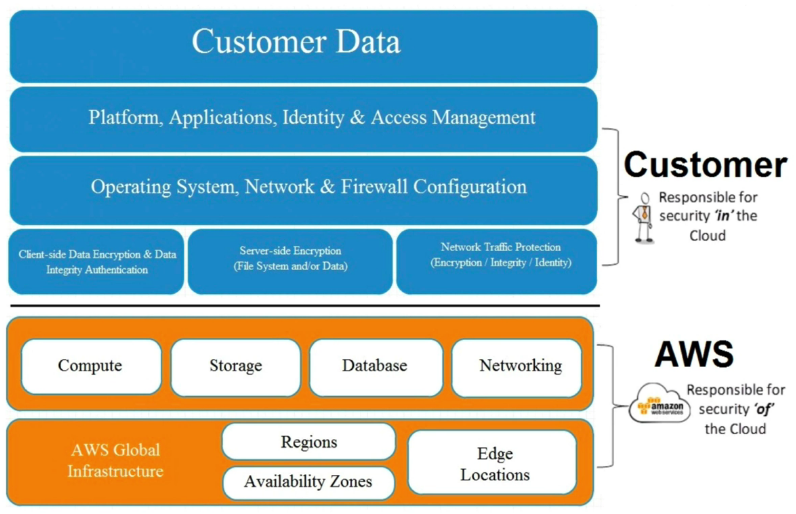
- Focus on securing your system
- What is the client responsible for? (See image below)
- Securing the data
- The application
- The Operating system
- What is the client responsible for? (See image below)
- Automate security best practices
- The center for Internet Security
- Harden your OS and create an AMI
- All auto-scaled instances will be secured from the word go.
Definition (Need to remember these definitions!)
Data Protection
Before starting the design, data should be organized and classified into segments, such as:
- Publicly available
- Only within your organization
- Only to specific members of your organization
- The B.O.D.
Each segment should be protected by with a ‘least privilege’ access system so people can only access what they need. Additionally, data should be encrypted where ever possible, be it at rest or in transit (HTTPS).
Best Practices
In AWS, the following practices help to protect your data:
- AWS customers maintain full control over their data.
- AWS makes it easier for your to encrypt your data and manage keys, including regular key rotation, which can be easily automated natively by AWS or maintained by a customer. (Key Management Services)
- Detailed logging is available that contains important content, such as file access and changes. (CloudTrail)
- AWS has designed storage systems for exceptional resiliency. Example: S3 is designed for 11 nines of durability. (if you store 10,000 objects with S3, you can expect to incur a loss of a single object once every 10,000,000 years.)
- Versioning, which can be part of a larger data lifecycle management process and can protect against accidental overwrites, deletes and similar harm.
- AWS never initiates the movement of data between regions. Content placed in a region will remain in that region unless the customer explicitly enables a feature or leverages a service that provides that functionality.
Questions to Ask
- How are you encrypting your data at rest?
- How are you encrypting your data in transit? (SSL)
Privilege Management
Privilege Management ensures that only authorized and authenticated users are able to access your resources, and only in a manner that is intended. It can include:
- Access Control Lists
- Role Based Access Controls
- Password Management (such as password rotation policies & password strength)
Questions to Ask
- How are you protecting access to and use of the AWS root account credentials?
- Have you enabled MFA?
- How are you defining roles and responsibilities of system users to control human access to the AWS Management Console and APIs?
- Are users divided into groups that allow access only to what they need?
- How are you limiting automated access (such as from apllications, scripts, or their-party tools or services) to AWS resources?
- How are you managing keys and credentials?
Infrastructure Protection
Outside of Cloud, this is how you protect your data center. RFID controls, security, lockable cabinets, CCTV etc. Within AWS they handle this, so really Infrastructure protection exists at your VPC level.
- How are you protecting your VPC
- What security groups are in place?
- What ACLs are in place?
- Is the subnet public or private?
Questions to ask
- How are you enforcing network and host-level boundary protection?
- Are you just using Security Groups or are you also using Network ACLs?
- Are you using Public and Private subnets?
- Are you using Bastion hosts for the private instances?
- What users have access to these services? Root or other users also?
- How are you enforcing AWS service level protection?
- Do you have multiple users that are able to log into the console?
- Do you have groups set up so different users have different privileges?
- Do you have MFA enabled?
- Do you have a strong password protection/rotation policy?
- How are you protecting the integrity of the operating systems on your EC2 instances?
- If Windows, do you have Anti-virus installed?
Detective Controls
You can use detective controls to detect or identify a security breach. AWS Services to achieve this include:
- CloudTrail
- CloudWatch
- CPU or RAM goes through the roof
- Config
- S3
- Glacier
Questions to ask
- How are you capturing and analyzing AWS logs?
- Is CloudTrail turned on in each Region in which you are operating?
- Are you using any 3rd party virtual instances such as IDS/IPS as provided by Alert Logic?
Best Practices
Key AWS Services
- Data Protection
- Encrypt your data both in transit and at rest
- ELB
- EBS
- S3
- RDS
- Encrypt your data both in transit and at rest
- Privilege Management
- IAM
- MFA
- Infrastructure Protection
- VPC
- Security Groups
- Network ACLs
- Detective Controls
- CloudTrail
- Config
- CloudWatch
Resources
Pillar 1 – Security: Exam Tips
- Know the 4 areas of Security
- Data Protection
- Privilege Management
- Infrastructure Protection
- Detective Controls
- Know some of the questions to ask for each area
- Data Protection
- How protecting and encrypting your data at rest?
- How protecting and encrypting your data in transit?
- Privilege Management
- How are you protecting access to and use of the AWS root account credentials?
- How are you defining roles and responsibilities of sysem users to control human access to the AWS Management Console and APIs?
- How are you limiting automated access (such as from applications, scripts, 3rd party tools or services) to AWS resources?
- Are you using Roles???
- How are you managing Keys and credentials?
- Infrastructure Protection
- How are you enforcing network and host-level boundary protection?
- How are you enforcing AWS sercie level protection?
- How are you protecting the integrity of the OS?
- Anti-virus?
- Detective Controls
- How are you capturing and analyzing your AWS logs?
- Are you USING CloudTrail?
- How are you capturing and analyzing your AWS logs?
- Data Protection
Pillar 2 – Reliability
The reliability pillar covers the ability of a system to recover from service or infrastructure outages/disruptions as well as the ability to dynamically acquire computing resources to meet demand.
Design Principles
- Test recovery procedures
- Simulate different failures (turn off key instances/resources)
- Recreate scenarios that led to failures previously
- Automatically recover from failure
- Use Key Performance Indicators (KPIs) system monitoring to trigger events (automation) when a threshold is breached. (Scaling up/down)
- Scale horizontally to increase aggregate system availability
- Use multiple smaller instances instead of 1 larger one to reduce the impact of a single instance failure.
- Stop guessing capacity
- Under provision and you will experience issues when limits are exceeded or during peak times.
- Over provision and you’re waisting money.
- Manage changes through Automation.
- Changes to infrastructure should be done using automation. The changes that need to be managed are changes to the automation.
Definition
Reliability in the cloud consists of 3 areas:
- Foundations
- Change Management
- Failure Management
Best Practices
Foundations
“Before building a house, make sure that the foundation is securely in place before laying the first brick.”
- In a traditional Datacenter world: Mis-provisioning during the initial design/build can cause significant delays or other issues at deployment
- In AWS, the cloud is designed to be essentially limitless
- AWS can handle the networking and compute requirements
- They do set service limits to stop customers from accidentally over-provisioning.
Foundation questions to ask
- How are you managing AWS service limits for your account?
- How are you planning your network topology on AWS?
- Do you have an escalation path to deal with technical issues?
- Do we need to upgrade our level of services so we have an account manager?
Change Management
You need to be aware of how change affects a system so that you can plan proactively around it. Monitoring allows you to detect any changes to your environment and react.
- In traditional systems, change control is done manually and are carefully coordinated with auditing.
- With AWS, you can use CloudWatch to monitor the environment and use services such as autoscaling to automate change in response to changes in the production environment.
Change Management questions to ask
- How does your system adapt to changes in demand?
- How are you monitoring your AWS resources?
- How are you executing change management?
Failure Management
With cloud, you should always architect your systems with the assumptions that failures will occur. You should become aware of these failures, how they occurred, how to respond to them and then plan on how to prevent these from happening again.
Failure Management questions to ask.
- How are you backing up your data?
- How does your system withstand component failures?
- How are you testing for resiliency?
- How are you planning for recovery?
Key AWS Services
- Foundations
- Identity Access Management
- VPC
- Change Management
- CloudTrail
- Config
- Failure Management
- CloudFormation (Provides templates for the creation of resources and provisions them in an orderly and predictable fashion.
- Also recommend (but not listed in the white paper)
- CloudWatch/Auto Scaling
- RDS & Multi-AZ
Exam Tips
- Reliability in the cloud consists of 3 areas:
- Foundations
- Change management
- Failure management
- Foundations
- How are you managing AWS service limits for your account?
- How are you planning your network topology on AWS?
- Do you have an escalation path to deal with technical issues?
- Change Management
- How does your system adapt to changes in demand?
- How are you monitoring AWS resources?
- How are you executing change management?
- Failure Management
- How are you backing up your data?
- How does your system withstand component failures?
- How are you planning for recovery?
Pillar 3 – Performance Efficiency
https://www.udemy.com/aws-certified-solutions-architect-associate/learn/v4/t/lecture/5267852?start=0
The Performance Efficiency pillar focuses on how to use computing resources efficiently to meet your requirements and how to maintain that efficiency as demand changes and technology evolves.
Design Principles
- Democratize advanced technologies
- Rather than having your IT team learn how to hose and run a new technology, they can simply consume it as a service
- NoSQL Databases
- media transcoding
- Machine Learning
- Rather than having your IT team learn how to hose and run a new technology, they can simply consume it as a service
- Go global in minues
- Use CloudFormation to provision your environment in different regions globally.
- Use serverless architectures
- Removes the need to run and maintain servers.
- Use storage for static web pages and content
- Event services host your code
- These can drastically lower operational costs because you are only paying for EXACTLY what you use!
- Removes the need to run and maintain servers.
- Experiment more often
- Try using different instance types to see if you can achieve the same results at lower costs.
- Mechanical Sympathy
- Use the technology approach that aligns best with what you are trying to achieve. Consider actual patterns of usage when determining the best database or storage solutions.
Definition
- Selection
- Compute
- Storage
- Database
- Space-time trade-off
- Network
- Review
- Monitoring
- Tradeoffs
Best Practices
Selection – Compute
- When architecting your system, it is important to choose the right kind of server
- CPU heavy
- I/O heavy
- Ram heavy
- Serverless?
- Ability to change at virtually the click of a button or API call.
Compute Questions to ask
- How do you select the appropriate instance type for your system?
- How do you ensure that you continue to have the most appropriate instance type as new instance types and features are introduced?
- How do you monitor your instances post launch to ensure they are performing as expected?
- How do you ensure that the quantity of your instances matches demand?
Selection – Storage
The optimal storage solutions for your environment depends on a number of factors. For example:
- Access Method – Block, File or Object?
- Patterns of Access – Random or Sequential
- Throughput Required
- Frequency of Access – Online, Offline (infrequently accessed) or Archival
- Frequency of Update – WORM (Write Once, Read Many), Dynamic
- Availability Constraints
- Durability Constraints
Options:
- S3
- 11 -9’s with S3
- Cross-Region replication
- EBS
- SSD
- Magnetic
- Provisioned IOPs
- Ability to change by creating and restoring snapshots.
Storage questions to ask
- How do you select the appropriate storage solution for your system?
- How do you ensure that you continue to have the most appropriate storage solution as new storage solutions and features are launched?
- How do you monitor your storage solution to ensure it is performing s expected?
- How do you ensure that the capacity and throughput of your storage solutions matches demand?
Selection – Databases
The optimal database solution depends on a number of factors. Do you need:
- Database consistency?
- High availability?
- NoSQL?
- DR?
Database questions to ask
- How do you select the appropriate database solution for your system?
- How do you ensure that you continue to have the most appropriate database solution and features as new database solution and features are launched?
- How do you monitor your databases to ensure performance is as expected?
- How do you ensure the capacity and throughput of your databases matches demand?
Selection – Network (aka Space-Time Trade Off)
This could be re-labeled “How to lower latency”
- Use Read Replicas to reduce load on the primary DB and put the replica close to the destination?
- Use DirectConnect to optimize and have predictable latency between HQ and AWS
- Use Global Infrastructure to put your environment in regions close to your customers.
- Use ElastiCache or CloudFront
Network questions to ask
- How do you select the appropriate proximity and caching solutions for your system?
- How do you ensure that you continue to have the most appropriate proximity and caching solutions as new solutions are launched?
- How do you monitor your proximity and caching solutions ensure performance is as expected?
- How do you ensure that the proximity and caching solutions you have matches demand?
Key AWS Services
- Compute
- Autoscaling
- Storage
- S3, EBS, Glacier
- Database
- RDS, DynamoDB, Redshift
- Networking
- CloudFront, ElastiCache, Direct Connect, RDS Read Replicas
Exam Tips
- Know the 4 different areas of Performance Efficiencies
- Compute
- Storage
- Database
- Network
- Remember the 4 types of questions for each
- How do you select the right one?
- How do you stay up to date as new options are released?
- How are you monitoring and testing what you have?
- How do you make sure what you have matches your demaind.
Resources
Pillar 4 – Cost Optimization
https://www.udemy.com/aws-certified-solutions-architect-associate/learn/v4/t/lecture/5267856?start=0
Use the Cost Optimization pillar to reduce your costs to a minimum and use those savings for other parts of your business. A cost-optimized system allows you to pay the lowest price possible while still achieving your business objectives.
Design Principles
- Transparently attribute expenditure.
- This expense was consumed by Dept. X and that was Dept. Y.
- Tags?
- Use managed services to reduce cost of ownership
- Email services?
- Trade capital expense for operating expense
- Spin up Dev and you need it and destroy when you’re not
- Benefit from economies of scale
- AWS buys in super-mega bulk and gets deep discounts you could not get on your own.
- Stop spending money on data center operations.
- Operational Overhead
Definition
- Match Supply and Demand
- Cost-effective resources
- Expenditure awareness
- Optimizing over time
Best Practices
Match Supply and Demand
Try to optimally align supply with demand. Don’t over provision or under provision. Instead, as demand grows, so should your supply of compute resources.
- Autoscaling
- Lambda (serverless) which only executes when a request is generated.
- CloudWatch can be used to keep track of what your demand is.
Supply and Demand questions to ask
- How do you make sure your capacity matches but does not substantially exceed what you need?
- How are you optimizing your usage of AWS services?
Cost-Effective Resources
Using the correct instance type can be key to cost savings. Fore example, you might have a reporting process that is running on a t2.micro and takes 7 hrs to complete. That same process could be run on an m4.2xlarge in a matter of minutes. The result remains the same but the t2.micro is more expensive because it ran much longer.
A well architected system will use the most cost efficient resources to reach the end of business goal.
Cost-Effective Resources questions to ask
- Have you selected the appropriate resource types to meet your cost targets?
- Have you selected the appropriate pricing model to meet your cost targets?
- Are there managed services (AWS SaaS) that you can use to improve your ROI (Return On Investment)
Expenditure Awareness
With Cloud, you no longer have to go and get quotes on physical servers, choose a supplier, wait for delivery, install and configure the new hardware before you can use it. You can provision things within seconds, however this comes with its own issues. Many organizations have different teams, each with their own AWS accounts. Being aware of what and where each team is spending is crucial to any well architected system. You can use cost allocation tags to track this, billing alerts as well as consolidated billing.
Expenditure Awareness questions to ask
- What access controls and procedures do you have in place to govern AWS costs?
- How are you monitoring usage and spending?
- How do you decommission resources that you no longer need, or stop resources that are temporarily not needed?
- How do you consider data-transfer charges when designing your architecture?
Optimizing Over Time
AWS moves FAST! There are hundreds of new services (and potentially 1000 new services this year). A service that you chose yesterday may not be the best service to be using today. For example consider MySQL RDS: Aurora was launched at re:invent 2014 and is now out of preview. Aurora may be a better option now for your business because of its performance and redundancy. You should keep track of the changes made to AWS and constantly re-evaluate your existing architecture. You can do this by:
- Subscribing to the AWS blog
- Using service such as Trusted Advisor.
Optimizing Over Time questions to ask
- How do you manage and/or consider the adoption of new services?
Key AWS Services
- Matched Supply and Demand
- Autoscaling
- Lambda
- Cost-Effective Resources
- EC2 Reserved instances
- Spot Instances
- AWS Trusted Advisor
- Expenditure Awareness
- Tags
- CloudWatch Alarms
- SNS
- Billing Alerts
- Optimizing Over Time
- AWS Blog
- Trusted Advisor
Exam Tips
- 4 Areas
- Matched Supply and Demand
- How do you make sure your capacity matches but does not substantially exceed what you need?
- How are you optimizing your usage of AWS services?
- Cost-effective resources
- Have you selected the appropriate resource types to meet your cost targets?
- Have you selected the appropriate pricing model to meet your cost targets?
- Are there managed services (AWS SaaS) that you can use to improve your ROI (Return On Investment)
- Expenditure Awareness
- What access controls and procedures do you have in place to govern AWS costs?
- How are you monitoring usage and spending?
- How do you decommission resources that you no longer need, or stop resources that are temporarily not needed?
- How do you consider data-transfer charges when designing your architecture?
- Optimizing over time
- How do you manage and/or consider the adoption of new services?
- Matched Supply and Demand
Pillar 5 – Operational Excellence
The Operational Excellence pillar includes operational practices and procedures used to manage production workloads. This includes how planned changes re executed, as well as responses to unexpected operational events. Change execution and responses should be automated. All processes and procedures of operational excellence should be documented, tested and regularly reviewed.
Design Principles
- Perform operations with code
- Align operations processes to business objectives
- Collect metrics that your business objectives are being met.
- Make regular, small incremental changes
- Test for responses to unexpected events
- Learn from operational events and failures
- Keep operations procedures current
Definition
- Preparation
- Operation
- Response
Best Practices
Preparation
Effective preparation is required to drive operational excellence. Operations checklists will ensure that workloads are ready for production operation and prevent unintentional production promotion without effective preparation.
Documentation is king!
Be sure that documentation does not become stale or out of date as procedures change. Also make sure that it is thorough. Without application designs, environment configurations, resource configurations, response plans, and mitigation plans, documentation is not complete! If documentation is not updated and tested regularly, it will not be useful when unexpected operational events occur. If workloads are not reviewed before production, operations will be affected when undetected issues occur. If resources are not documented, when operation events occur, determining how to respond will be more difficult while the correct resources are identified.
Workloads should have:
- Runbooks – Operations guidance that operations teams can refer to so they can perform normal daily tasks.
- Day to Day Operations
- Playbooks – Guidance for responding to unexpected operational events. Playbooks should include response plans, as well as escalation paths and stakeholder notifications.
- Escalation path and procedures.
Preparation questions to ask
- What best practices for cloud operations are you using?
- How are you doing configuration management for your workload?
Operations
Operations should be standardized and manageable on a routine basis. The focus should be on automation, small frequent changes, regular quality assurance testing and defined mechanisms to track, audit, roll back and review changes. Changes should not be large and infrequent nor should they require scheduled downtime nor manual execution. A wide range of logs and metrics that are based on key operational indicators for a workload should be collected and reviewed to ensure continuous operations.
With AWS you can set up a continuous integration / continuous deployment (CI/CD) pipeline (e.g. source code repository, build systems, deployment and testing automation.) Release management processes, whether manual or automated, should be tested and based on small incremental changes, and tracked versions. You should be able to revert changes that introduce operational issues without causing operational impact.
Routine operations, as well as responses to unplanned events, should be automated. Manual processes for deployments, release management, changes and rollbacks should be avoided. Releases should not be large batches that are done infrequently. Rollbacks are more difficult in large changes, and failing to have a rollback plan, or the ability to mitigate failure impacts will prevent continuity of operations. Align monitoring to business needs, so that the responses are effective at maintaining business continuity. Monitoring that is ad hoc and not centralized, with responses that are manual, will cause more impact to operations during unexpected events.
Operations questions to ask
- How are you evolving your workload while minimizing the impact of change?
- How do you monitor your workload to ensure it is operating as expected?
Responses
Responses to unexpected operational events should be automated. This is not just for alerting, but also for mitigation, remediation, rollback and recovery. Alerts should be timely and should invoke escalations when responses are not adequate to mitigate the impact of operational events. Quality assurance mechanisms should be in place to automatically roll back failed deployments. Responses should follow a per-defined play book that includes stakeholders, the escalation process and procedures. Escalation paths should be defined and include both functional and hierarchical escalation capabilities. Hierarchical escalation should be automated and escalated priority should result in stakeholder notifications.
In AWS, there are several mechanisms to ensure both appropriate alerting and notification in response to unplanned operational events, as well as automated responses.
Response questions to ask
- How do you respond to unplanned operational events?
- How is escalation managed when responding to unplanned operational events?
Key AWS Services
- Preparation
- CloudFormation
- Reduces potential for human error
- All CloudFormation implemenations should be fully tested before putting into production to ensure reliability.
- Auto Scaling
- AWS Config
- Provides a detailed inventory of your AWS resources and configurations.
- Continuously records configuration changes.
- AWS Service Catalog
- Create a standardized set of service offerings that are aligned to best practices.
- Tagging
- CloudFormation
- Operations
- CodeCommit
- CodeDeploy
- CodePipeline
- SDKs (Software Development Kits)
- CloudTrail
- Response
- CloudWatch + SNS
Exam Tips
Operational Excellence consists of 3 areas
- Preparation
- What best practices for cloud operations are you using?
- How are you doing configuration management for your workloads?
- Operation
- How are you evolving your workload while minimizing the impact of change?
- How do you monitor your workload to ensure it is operating as expected?
- Responses
- How do you respond to unplanned operational events?
- How is escalation managed when responding to unplanned operational events?
Summary of the Well Architected Framework
https://www.udemy.com/aws-certified-solutions-architect-associate/learn/v4/t/lecture/5267868?start=0
What are the 5 Pillars?
- Security
- Reliability
- Performance Efficiency
- Cost Optimization
- Operational Excellence
Security
- Data Protection (Encryption)
- How are you encrypting your data at rest?
- How are you encrypting your data in transit? (SSL)
- Privilege Management
- How are you protecting access to and use of the AWS root account credentials? (MFA)
- How are you defining roles and responsibilities of system users to control human access to the AWS Management Console and APIs? (Groups?)
- How are you limiting automated access (such as from applications, scripts, or 3rd party tools or services) to AWS resources? (Roles from Identity Access Management)
- How are you managing keys and credentials?
- Infrastructure Protection (Handled by AWS)
- How are you enforcing network and host level boundary protection?
- How are you enforcing AWS service level protection?
- How are you protecting the integrity of the operating systems on your EC2 instances?
- Detective Controls (CloudTrail)
- How are you capturing and analyzing AWS logs? (CloudWatch, CloudTrail – Verify!)
Reliability
(These seem to be the same as Pillar 5 – Operational Excellence)
- Foundations (Preparations)
- How are you managing AWS service limits for your account? (Billing alerts?)
- How are you planning your network topology on AWS?
- Do you have an escalation path to deal with technical issues?
- AWS Technical Account Manager?
- Change Management (Operations)
- How does your system adapt to changes in demand? (Auto Scaling)
- How are you monitoring AWS resources?
- How are you executing change management? (Automated via Auto Scaling)
- Failure Management (Responses)
- How are you backing up your data?
- How does your system withstand component failures?
- How are you planning for recovery?
Performance Efficiency
Each set of 4 questions is pretty much the same for each key area
- Compute
- How do you select the appropriate instance type for your system
- How do you ensure you continue to have the right type as new types and features are introduced?
- How are you monitoring these systems to ensure they perform as expected
- How do you ensure you have the correct quantity of these instances?
- Storage
- How do you select the appropriate storage type for your system
- How do you ensure you continue to have the right type as new types and features are introduced?
- How are you monitoring these systems to ensure they perform as expected
- How do you ensure you have enough capacity and throughput to match your demand?
- Database
- How do you select the appropriate database solution for your system
- How do you ensure you continue to have the right type as new types and features are introduced?
- How are you monitoring these systems to ensure they perform as expected
- How do you ensure you have enough capacity and throughput to match your demand?
- Network (Space-time trade-off)
- How do you select the appropriate proximity and caching solutions for your system
- How do you ensure you continue to have the right proximity and caching solutions as new types and features are introduced?
- How are you monitoring your proximity and caching solutions to ensure they perform as expected
- How do you ensure that the proximity and caching solutions you have match your demand?
Cost Optimization
- Matched supply and demand
- How do you make sure your capacity matches but does not substantially exceed your demand?
- How are you optimizing your usage of AWS services?
- Cost-effective resources
- Have you selected the appropriate resource types to meet your cost targets?
- Have you selected the appropriate pricing model to meet your cost targets?
- Are there managed services (SaaS) that you can use to improve your ROI?
- Expenditure awareness
- What access controls and procedures do you have in place to govern AWS costs?
- How are you monitoring usage and spending?
- How do you decommission resources that you no longer need, or stop resources that are temporarily not needed?
- How do you consider data-transfer charges when designing your architecture?
- Optimization over time
- How do you manage and/or consider the adoption of new services as they become available to you? (Subscribe to the AWS blog!)
Operational Excellence
(Still think this is the same as Pillar #3, Reliability)
- Preparation
- What best practices for cloud operations are you using?
- How are you doing configuration management for your workload?
- Operations
- How are you evolving your workload while minimizing the impact of change?
- How do you monitor your workload to ensure it is operating as expected?
- Responses
- How do you respond to unplanned operational events?
- How is escalation managed with responding to unplanned operational events?