Section 5: Efficient Schema Design in BigQuery
25. Design an Efficient schema for BigQuery Tables
https://www.udemy.com/course/bigquery/learn/lecture/22735695#questions
Nested and Repeated Columns
- Works best when denormalized
- Rather than preserving relational schema, such as star or snowflake
- Normalization
- Technique to eliminate redundant data to minimize the insertion, deletion and update anomalies
- Saves a lot of space
- Involved multiple tables where
- the core data is organized into one table
- Related data is stored in different tables.
- Data is often fetched by including multiple tables through relationships to each other
- Usually on some key: order_id or customer_id
- Reduces redundancy and preserves data integrity
- Queries run slower: More tables to join, the queries have to jump from table to table
- Denormalization
- Strategy of allowing duplicate files values for a column in a table to gain processing performance
- Put everything in 1 tables and don’t care about redundancy.
- Performance improved because no need to jump between tables.
- Denormalized data can be processed in parallel using columnar processing.
- Downside:
- Can reduce performance where there are 1 – to – Many relationships
- Grouping by Order_Id where there is a lot of repetitive data
- Can reduce performance where there are 1 – to – Many relationships
- BQ supports both Nested and Repeated data
- Nested is synonym for Struct data type
- Repeated is like an Array
- In short, you have an array of structs.
- Nested and Repeated columns maintain relationships without impacting performance of a normalized schema
Example:
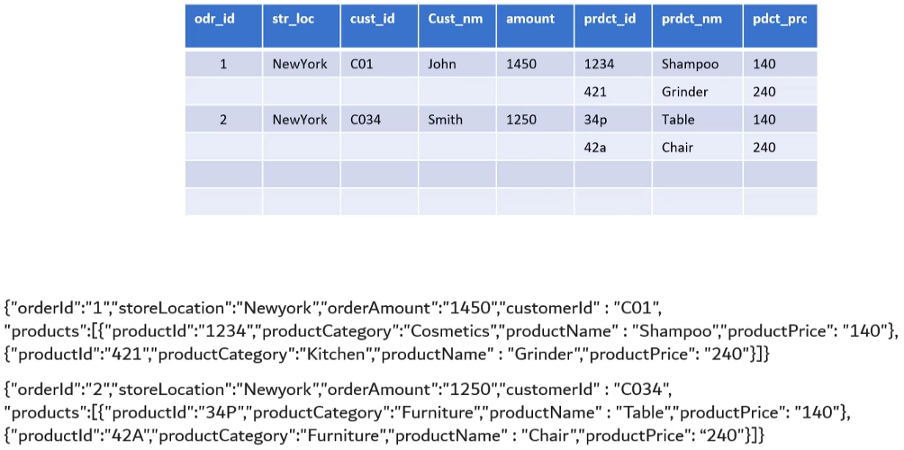
{
orderId: 1,
storeLoc: Newyork,
orderAmt: 1450,
custId: C01,
products: [
{
prodId: 1234,
prodCat: Cosmetics
prodName: Shampoo
prodPrice: 140
},{
prodId: 421
prodCat: Kitchen
prodName: Grinder
prodPrice: 240
}
]
},
{
orderId: 2,
storeLoc: Newyork,
...
- The Products field is a Nested and Repeated field
- Repeated because it is an array
- Nested because it is a Struct
- These can be imported from
- JSON, Avro, Firestore exports and Datastore export files
26. Nested and Repeated Columns
https://www.udemy.com/course/bigquery/learn/lecture/22730017#questions
- When importing a JSON, you should be able to use Schema Auto Detect.
- The downside is all fields will be nullable.
- This is not good because we would require orderId and productId to be filled.
- Will need to create the schema manually.
- First, specify the normal fields
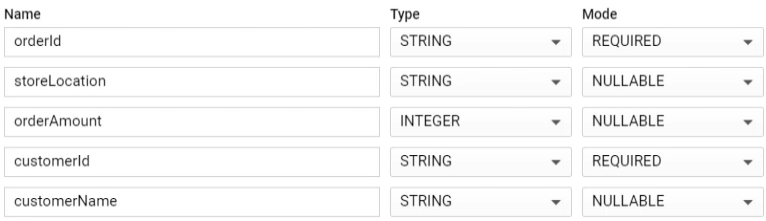
- Then create the Repeated Array
- Type: RECORD = Struct
- Click the [+] symbol to add the array elements
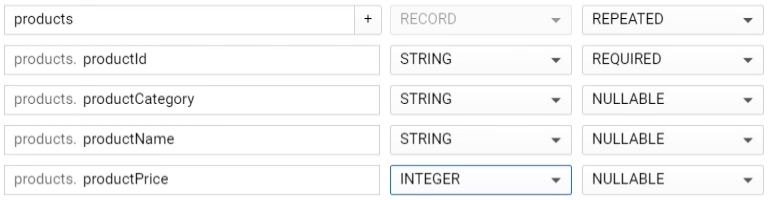
- Finally, click [Create table]
How to query this table

Query this table where productName = Table
- You have to “unnest” the array so each “flattened” row gets attached with its root columns
SELECT * from `PROJECT.DATASET.TABLE` CROSS JOIN unnest(products) as my_field WHERE my_field.productName = "TABLE"
- You can now access all flattened columns as normal columns directly using ‘my_field.COLNAME’ and apply any mathematical, string, or any function on it.
CROSS JOIN
- is an expensive process so only select the columns you need
SELECT orderId, storeLocation, my_field.* from `PROJECT.DATASET.TABLE` CROSS JOIN unnest(products) as my_field WHERE my_field.productName = "TABLE"
You can replace CROSS JOIN with a comma
SELECT orderId, storeLocation, my_field.* from PROJECT.DATASET.TABLE, unnest(products) as my_field WHERE my_field.productName = "TABLE"
Other Schemas
- BQ also supports
- 3NF
- Snowflake
- Star
- Use Nested and Repeated when your data naturally fits this data type
- Best for performance
- Use the others if that is the format it is provided in
Assignment #2
https://www.udemy.com/course/bigquery/learn/practice/1257626#questions
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
Assignment: Pull all fields where city = “Portland”
select id, first_name, last_name, dob, addr.* from `multi-340710.repnest.assg2`, unnest(addresses) as addr where city="Portland"
Observations
- You have to add the primary (non-nested) fields manually.
- “Portland” is case sensitive. This is different from MySQL